
In this article, you will learn what recursive language models are, why they matter for long-input reasoning, and how they differ from standard long-context prompting, retrieval, and agentic systems.
Topics we will cover include:
- Why long context alone does not solve reasoning over very large inputs
- How recursive language models use an external runtime and recursive sub-calls to process information
- The main tradeoffs, limitations, and practical use cases of this approach
Let’s get right to it.
Everything You Need to Know About Recursive Language Models
Image by Editor
Introduction
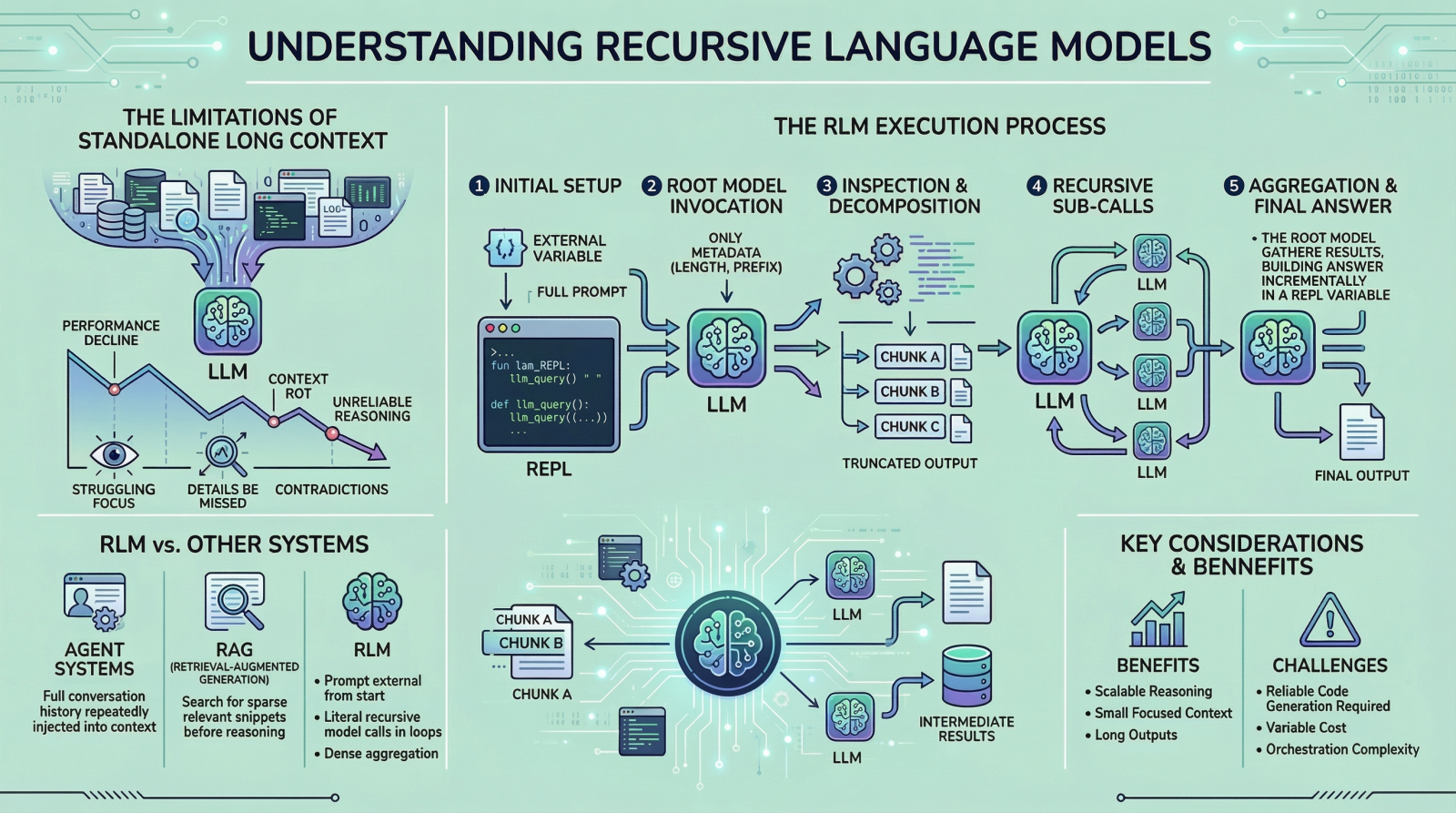
If you are here, you have probably heard about recent work on recursive language models. The idea has been trending across LinkedIn and X, and it led me to study the topic more deeply and share what I learned with you. I think we can all agree that large language models (LLMs) have improved rapidly over the past few years, especially in their ability to handle large inputs. This progress has led many people to assume that long context is largely a solved problem, but it is not. If you have tried giving models very long inputs close to, or equal to, their context window, you might have noticed that they become less reliable. They often miss details present in the provided information, contradict earlier statements, or produce shallow answers instead of doing careful reasoning. This issue is often referred to as “context rot”, which is quite an interesting name.
Recursive language models (RLMs) are a response to this problem. Instead of pushing more and more text into a single forward pass of a language model, RLMs change how the model interacts with long inputs in the first place. In this article, we will look at what they are, how they work, and the kinds of problems they are designed to solve.
Why Long Context Is Not Enough
You can skip this section if you already understand the motivation from the introduction. But if you are curious, or if the idea did not fully click the first time, let me break it down further.
The way these LLMs work is fairly simple. Everything we want the model to consider is given to it as a single prompt, and based on that information, the model generates the output token by token. This works well when the prompt is short. However, when it becomes very long, performance starts to degrade. This is not necessarily due to memory limits. Even if the model can see the complete prompt, it often fails to use it effectively. Here are some reasons that may contribute to this behavior:
- These LLMs are mainly transformer-based models with an attention mechanism. As the prompt grows longer, attention becomes more diffuse. The model struggles to focus sharply on what matters when it has to attend to tens or hundreds of thousands of tokens.
- Another reason is the presence of heterogeneous information mixed together, such as logs, documents, code, chat history, and intermediate outputs.
- Lastly, many tasks are not just about retrieving or finding a relevant snippet in a huge body of content. They often involve aggregating information across the entire input.
Because of the problems discussed above, people proposed ideas such as summarization and retrieval. These approaches do help in some cases, but they are not universal solutions. Summaries are lossy by design, and retrieval assumes that relevance can be identified reliably before reasoning begins. Many real-world tasks violate these assumptions. This is why RLMs suggest a different approach. Instead of forcing the model to absorb the entire prompt at once, they let the model actively explore and process the prompt. Now that we have the basic background, let us look more closely at how this works.
How a Recursive Language Model Works in Practice
In an RLM setup, the prompt is treated as part of the external environment. This means the model does not read the entire input directly. Instead, the input sits outside the model, often as a variable, and the model is given only metadata about the prompt along with instructions on how to access it. When the model needs information, it issues commands to examine specific parts of the prompt. This simple design keeps the model’s internal context small and focused, even when the underlying input is extremely large. To understand RLMs more concretely, let us walk through a typical execution step by step.
Step 1: Initializing a Persistent REPL Environment
At the beginning of an RLM run, the system initializes a runtime environment, typically a Python REPL. This environment contains:
- A variable holding the full user prompt, which may be arbitrarily large
- A function (for example,
llm_query(...)orsub_RLM(...)) that allows the system to invoke additional language model calls on selected pieces of text
From the user’s perspective, the interface remains simple, with a textual input and an output, but internally the REPL acts as scaffolding that enables scalable reasoning.
Step 2: Invoking the Root Model with Prompt Metadata Only
The root language model is then invoked, but it does not receive the full prompt. Instead, it is given:
- Constant-size metadata about the prompt, such as its length or a short prefix
- Instructions describing the task
- Access instructions for interacting with the prompt via the REPL environment
By withholding the full prompt, the system forces the model to interact with the input intentionally, rather than passively absorbing it into the context window. From this point onward, the model interacts with the prompt indirectly.
Step 3: Inspecting and Decomposing the Prompt via Code Execution
The model might begin by inspecting the structure of the input. For example, it can print the first few lines, search for headings, or split the text into chunks based on delimiters. These operations are performed by generating code, which is then executed in the environment. The outputs of these operations are truncated before being shown to the model, ensuring that the context window is not overwhelmed.
Step 4: Issuing Recursive Sub-Calls on Selected Slices
Once the model understands the structure of the prompt, it can decide how to proceed. If the task requires semantic understanding of certain sections, the model can issue sub-queries. Each sub-query is a separate language model call on a smaller slice of the prompt. This is where the “recursive” part actually comes in. The model repeatedly decomposes the problem, processes parts of the input, and stores intermediate results. These results live in the environment, not in the model’s context.
Step 5: Assembling and Returning the Final Answer
Finally, after enough information has been gathered and processed, the model constructs the final answer. If the output is long:
- The model incrementally builds it inside a REPL variable, such as
Final - Once
Finalis set, the RLM loop terminates - The value of
Finalis returned as the response
This mechanism allows the RLM to produce outputs that exceed the token limits of a single language model call. Throughout this process, no single language model call ever needs to see the full prompt.
What Makes RLMs Different from Agents and Retrieval Systems
If you spend time in the LLM space, you might confuse this approach with agentic frameworks or retrieval-augmented generation (RAG). However, these are different ideas, even if the distinctions can feel subtle.
In many agent systems, the full conversation history or working memory is repeatedly injected into the model’s context. When the context grows too large, older information is summarized or dropped. RLMs avoid this pattern entirely by keeping the prompt external from the start. Retrieval systems, by contrast, rely on identifying a small set of relevant chunks before reasoning begins. This works well when relevance is sparse. RLMs are designed for settings where relevance is dense and distributed, and where aggregation across many parts of the input is required. Another key difference is recursion. In RLMs, recursion is not metaphorical. The model literally calls language models inside loops generated as code, allowing work to scale with input size in a controlled way.
Costs, Tradeoffs, and Limitations
It is also worth highlighting some of the downsides of this method. RLMs do not eliminate computational cost. They shift it. Instead of paying for a single very large model invocation, you pay for many smaller ones, along with the overhead of code execution and orchestration. In many cases, the total cost is comparable to a standard long-context call, but the variance can be higher. There are also practical challenges. The model must be capable of writing reliable code. Poorly constrained models may generate too many sub-calls or fail to terminate cleanly. Output protocols must be carefully designed to distinguish intermediate steps from final answers. These are engineering problems, not conceptual flaws, but they still matter.
Conclusion and References
A useful rule of thumb is this: if your task becomes harder simply because the input is longer, and if summarization or retrieval would lose important information, an RLM is likely worth considering. If the input is short and the task is simple, a standard language model call will usually be faster and cheaper. If you want to explore recursive language models in more depth, the following resources are useful starting points: